
* Colab 사용법 실습 화면
01-3 마켓과 머신러닝
- 생선 분류 문제
- 데이터셋
- 도미 데이터 셋
2) 빙어 데이터 셋
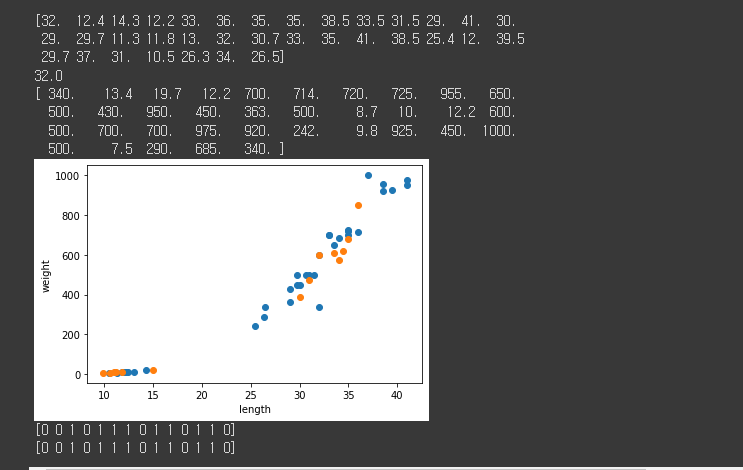
3) K-최근접 이웃 알고리즘 (k-Nearest Neighbors) 이용 도미와 빙어 데이터 구분하기
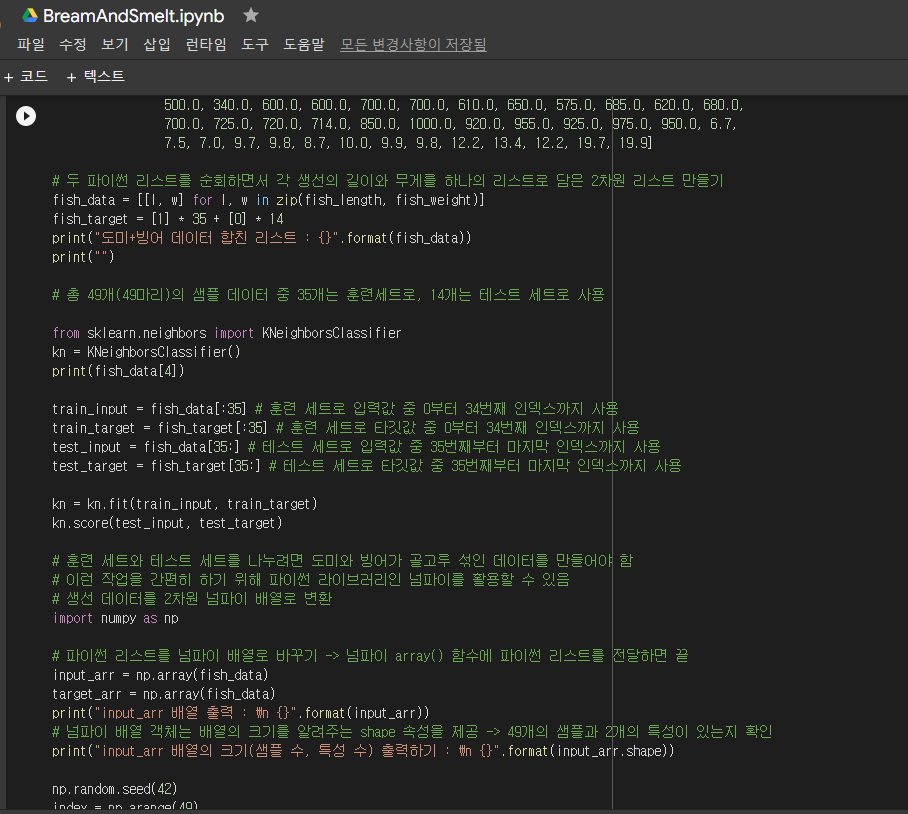
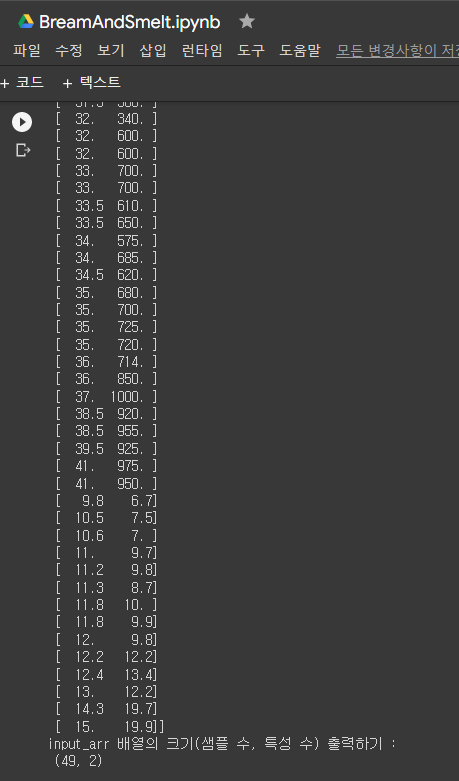
- 도미와 빙어 데이터 합치기(리스트 합치기)
* 전체 소스 코드 작성
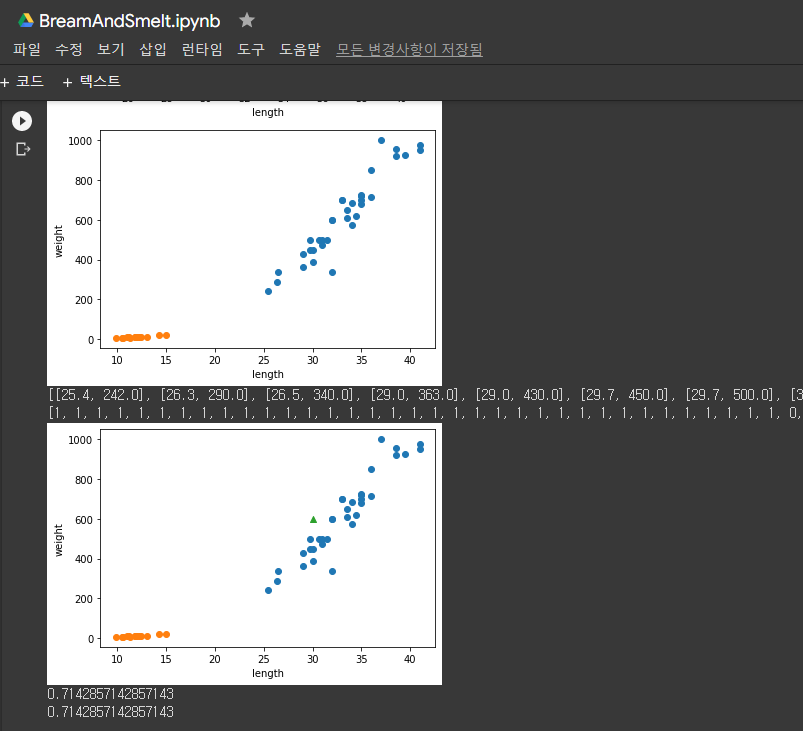
02-1) 훈련 세트와 테스트 세트
* 실습과정 (전체 소스 코드)
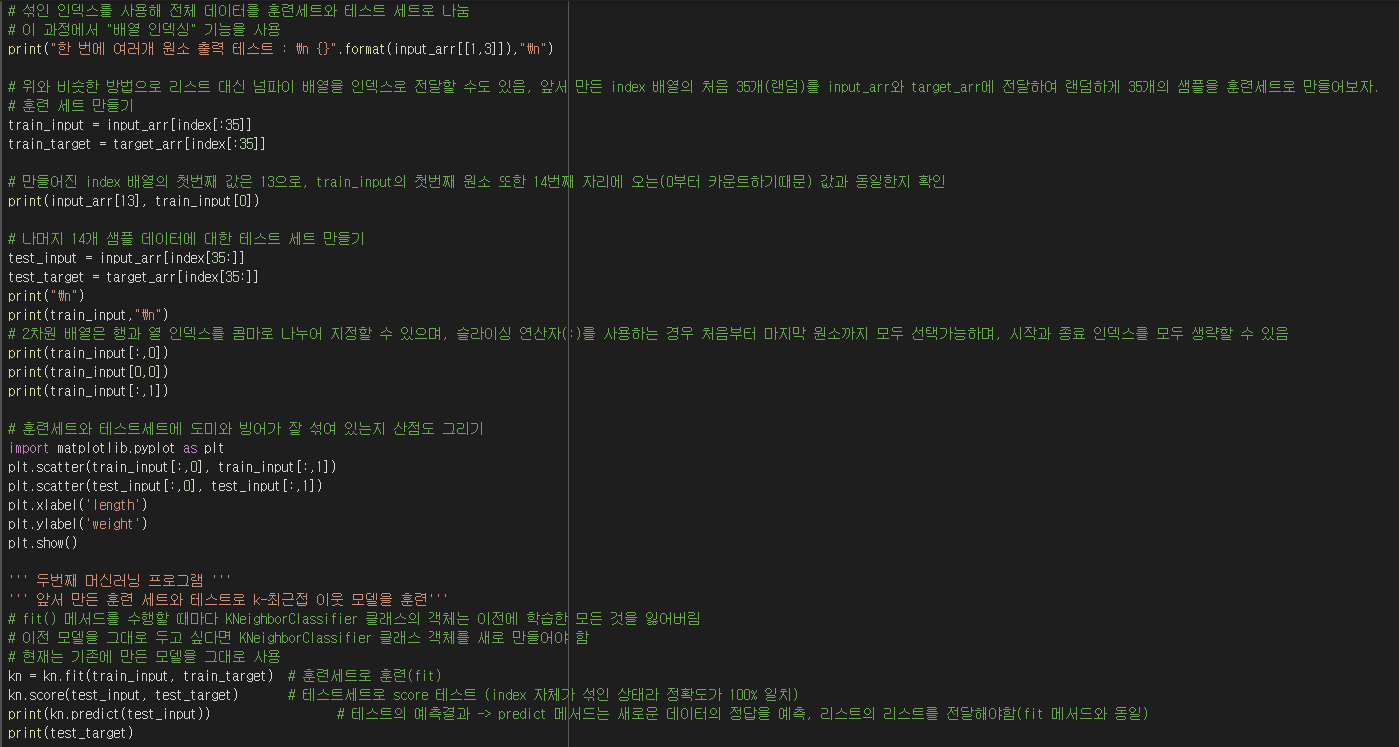
마무리
<키워드>
* 지도 학습 : 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는 데 활용. k-최근접 이웃이 지도 학습 알고리즘
* 비지도 학습 : 타깃 데이터가 없으며, 무엇을 예측하는 것이 아니라 입력 데이터에서 어떤 특징을 찾는 데 주로 활용
* 훈련 세트: 모델을 훈련할 때 사용하는 데이터. 보통 훈련 세트가 클수록 좋으며, 테스트 세트를 제외한 모든 데이터를 사용.
* 테스트 세트 : 전체 데이터에서 20~30%를 테스트 세트로 사용하는 경우가 많으며, 전체 데이터가 아주 크다면 1%만 덜어내도 충분할 수 있음
<핵심 패키지와 함수>
numpy
* seed() - 넘파이에서 난수를 생성하기 위한 정수 초기값을 지정하며, 초기값이 같으면 동일한 난수를 뽑을 수 있기 때문에 랜덤 함수의 결과를 동일하게 재현하고 싶을 때 사용
* arange() - 일정한 간격의 정수 또는 실수 배열을 만들며, 기본 간격은 1이다. 매개변수가 하나이면 종료숫자를 의미하고 종료 숫자 자체는 배열에 포함되지 않는다. arange(3)을 예로들면 0에서 부터 3까지의 배열을 만든다(종료숫자인 3은 제외)

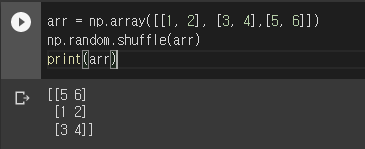
* shuffle() - 주어진 배열을 랜덤하게 섞는 함수. 다차원 배열일 경우 첫 번째 축(행)에 대해서만 섞는다.
- 02-1) 확인 문제
- 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은? → 지도 학습 (p.67)
- 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이고 부르나요? → 샘플링 편향 (p.73)
- 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?